Intro to GraphRAG
About GraphRAG
GraphRAG is Retrieval Augmented Generation (RAG) using a Knowledge Graph.
Have you ever stumbled upon the term GraphRAG while diving into the world of Retrieval Augmented Generation (RAG) systems? If so, you’re not alone. This term is making waves, but its meaning can be elusive. Sometimes, it’s a specific retrieval method; other times, it’s an entire software suite, like Microsoft’s GraphRAG “data pipeline and transformation suite.” With such varied uses, it’s no wonder even the most dedicated followers of RAG discussions can feel a bit lost.
So, what exactly is GraphRAG?
For us, it’s a set of RAG patterns that leverage a graph structure for retrieval. Each pattern demands a unique data structure, or graph pattern, to function effectively.

On this site, we’ll dive into the GraphRAG pattern details, breaking down each pattern’s attributes and strategies.
If you’re looking for an introduction to RAG, check out What Is Retrieval-Augmented Generation (RAG)?.
Each of our presented patterns is also linked directly to its GraphRAG Pattern Catalog entry. This catalog is an open source initiative to stay up to date on the latest pattern evolution.
NOTE: We just started collecting patterns and are definitely still missing a lot of them. Please help us build a comprehensive catalog for GraphRAG patterns and join the discussion on the GraphRAG Discord channel.
To give you a clearer picture, the patterns explained in this post include:
Basic GraphRAG Patterns
- Basic Retriever
- Pattern Matching
- Cypher Templates
- Graph-Enhanced Vector Search
- Metadata Filtering
- Parent-Child Retriever
Advanced GraphRAG patterns
- Dynamic Cypher Generation
- Global Community Summary Retriever
- Local Retriever
- Hypothetical Question Retriever
Knowledge Graph Models
- Domain Graph
- Lexical Graph
- Parent-Child Lexical Graph
- Lexical Graph with Sibling Structure
- Lexical Graph with Extracted Entities
- Lexical Graph with Extracted Entities and Community Summaries
- Lexical Graph with Hierarchical Structure
- Lexical Graph with Hypothetical Questions
- Memory Graph
- Text Sequence
Thematic Classification
According to Gao et al., there are three RAG paradigms: naive RAG, advanced RAG, and modular RAG:
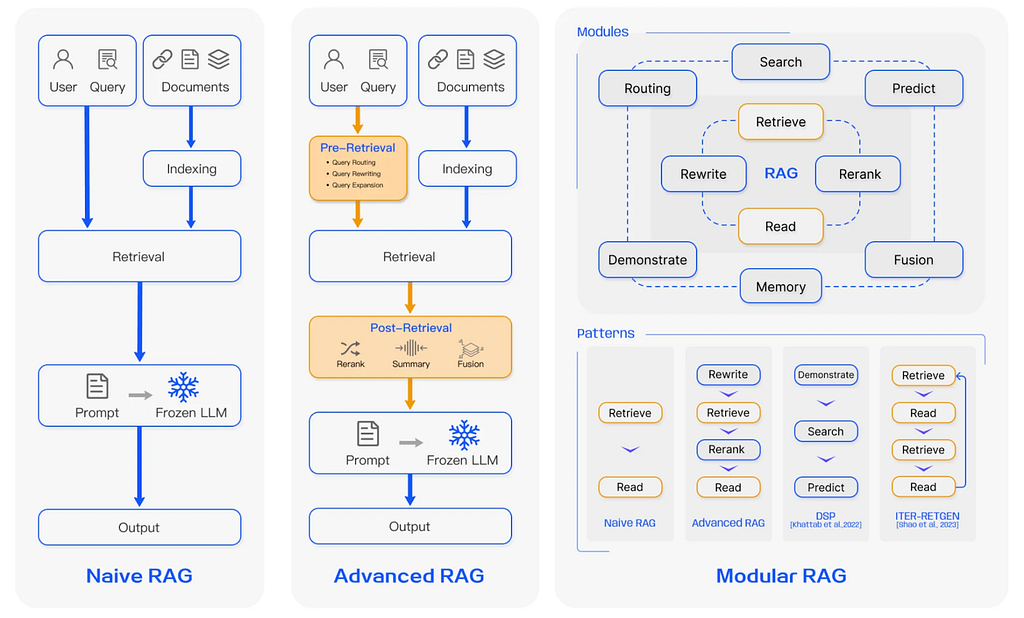
In an advanced RAG paradigm, pre-retrieval and post-retrieval phases are added to the naive RAG paradigm. A modular RAG system contains more complex patterns, which require orchestration and routing of the user query.
The phases of an advanced RAG system:
- Pre-retrieval — Query rewriting, query entity extraction, query expansion, etc.
- Retrieval of relevant context
- Post-retrieval: Reranking, pruning, etc.
- Answer generation
Here, we want to focus on the retrieval phase and compile a catalog of the most-often referenced GraphRAG retrieval patterns and their required graph patterns. Please note that the patterns here are not an exhaustive list.
How to GraphRAG
If you’re looking to implement the retrievers discussed here using the neo4j-graphrag package, LangChain, LlamaIndex, check their GraphRAG retriever integrations.
Here we focus on the intriguing part: using the retrieval_query to implement the GraphRAG patterns we discuss. The details of each pattern will include the corresponding query.
Remember, when crafting your query, there’s an invisible “first part” that performs the search operation to find your entry points into the graph (which can be vector, fulltext, spatial, hybrid or filters). The search part returns the found nodes and their similarity scores, which you can then use in your retrieval query to execute further traversals.
Here is an example of how this might look (example from LangChain Neo4j Vector documentation):
retrieval_query = """RETURN "Name: " + node.name AS text, score, {source:node.url} AS metadata"""retrieval_example = Neo4jVector.from_existing_index( OpenAIEmbeddings(), url=url, username=username, password=password, index_name="person_index", retrieval_query=retrieval_query,)retrieval_example.similarity_search("Jon Snow", k=1)In the above example, a vector similarity search is executed on the existing index person_index using the user input "Jon Snow" and returning the name, the score, and some metadata are returned for the one node with the best fit (k=1).